
[小小记录]Haihua AI Cup简单记录
开始
最先参加Haihua AI Cup的原因很简单:老师要求参加...
在学校信息课上,老师突然不继续讲之前上的课,让我们做一个Python题库(当然全是我们做过的),说是要“选拔比赛”,一开始我没什么兴趣,毕竟要忙的东西确实挺多的,老师又说是AI 比赛 第一名50kRMB , 二三名20kRMB, 我突然就来了兴趣,反正空闲的时间还算多,就玩玩吧。拉上2人,一起报了名。
回家LS老师加了我的QQ,把我拉进了一个群,感觉上了贼船,


开幕雷击
后来群里好像进来一个学长,来说比赛注意事项,并告诉了我们比赛网站 怎么tmd NFLS计算机学长全被LS拉过来当苦力

规则
规则写的还蛮长的,我反复阅读了几遍才搞懂规则: 做小学阅读理解!
具体的来说:
train.json中储存了阅读理解的训练数据,具体形式是
{
"ID": 1,
"Content": "文章内容",
"Questions": [
{
"Question": "问题内容",
"Choices": [
"A 选项内容",
"B 选项内容",
"C 选项内容",
"D 选项内容"
],
"Answer": "A",
"Q_id": "000101"
},
{
"Question": "问题内容",
"Choices": [
"A 选项内容",
"B 选项内容",
"C 选项内容",
"D 选项内容"
],
"Answer": "A",
"Q_id": "000102"
}
]
}
这是完整的一篇文章的形式,
另一个文件validation.json中文件格式则是这样的:
[
{
"ID":1,
"Content":"文章内容",
"Questions":[
{
"Question": "问题内容",
"Choices": [
"A 选项内容",
"B 选项内容",
"C 选项内容",
"D 选项内容"
],
"Q_id": "000101"
}
],
"Type": "00",
"Diff": 6
},
...
]
Type代表文本类别,具体包括 00 现代文 11文言文 22 古诗词 33现代诗词;Diff代表难度,具体包括 1 字词解释 2 标点符号作用 3 句子解释 4 填空 5选择正确读音 6 推理总结 7 态度情感 8 外部知识
最后一个文件sample.csv则是代表提交格式。
我一看到题目,两眼一抹黑,这可怎么办?从零开始学习自然语言学习和处理?事实上真干出来了可惜学到一半抛了
不幸中的万幸,比赛主办方提供了一个最基础的程序模板.
比赛的第一阶段,调参开始!
欢乐的调参时光
起初,我听从了比赛官方的指导,在matpool进行训练
充满信任地往里面充了20r,开了个4r/h的机器,心里还窃喜:这好便宜啊
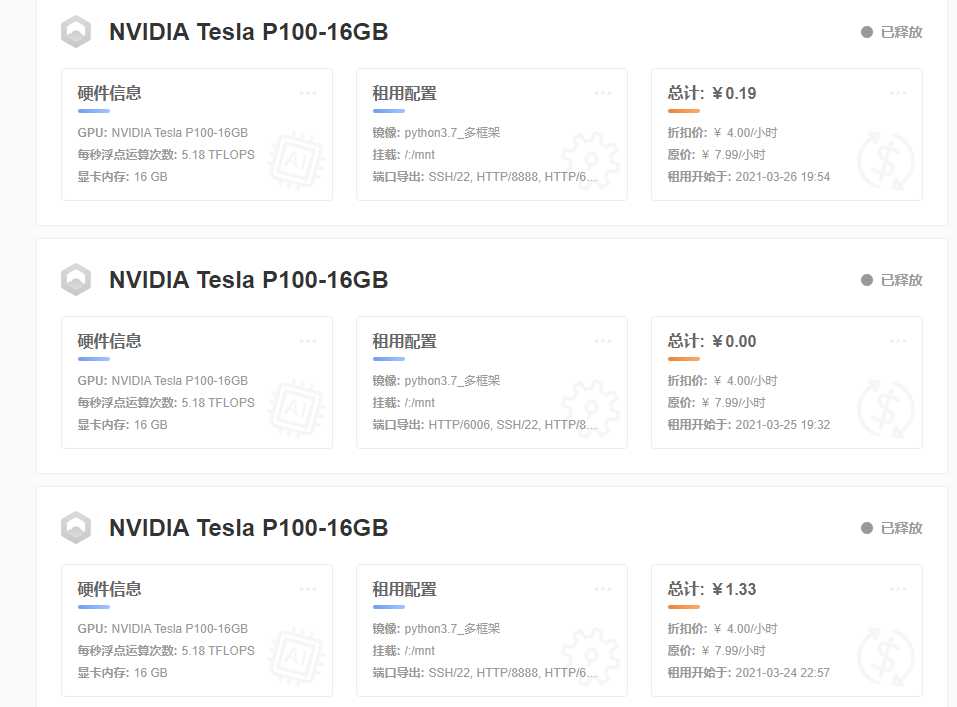
他给的环境也很友好,是Python Jupyter Notebook的网页版,可以直接运行.ipynb(也就是baseline的文件格式),可惜我一直忘记重启内核,导致装了依赖还是运行不了,一怒之下删机。之后正经跑了一下,好像发现要跑好长时间,遂罢。
这时候我想起了我们的老朋友--Google, Google Colab不是可以用GPU进行训练嘛? 开了个Colab Pro(强烈推荐,一个月只要$9.9就能用到高端显卡!), 并把500年不用的vps dd了个windows,就可以开始快乐的训练啦!

训练场景一
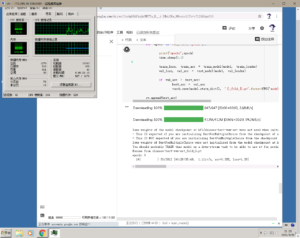
训练场景二
第一次提交就获得了55%的正确率!

CFG = { #训练的参数配置
'fold_num': 4, #五折交叉验证
'seed': 20170248,
'model': 'hfl/chinese-bert-wwm-ext', #预训练模型
'max_len': 256, #文本截断的最大长度
'epochs': 4,
'train_bs': 12, #batch_size,可根据自己的显存调整
'valid_bs': 12,
'lr': 2e-5, #学习率
'num_workers': 16,
'accum_iter': 2, #梯度累积,相当于将batch_size*2
'weight_decay': 1e-4, #权重衰减,防止过拟合
'device': 0,
}
config of 55%
之后渐渐地把参数调到了58%..也暂居了一段时间的榜一。(后面就被人反超了,,,)
比赛官方也不知道从哪找来一些人,半道杀出,取得前三的成绩...
欢乐的摸鱼时间
训练出58%的正确率后,就想不出来优化的方法了,一直卡在那
试过Roberta, ERNIE(失败了),还有规模稍大的中文模型,却只能眼睁睁地看自己被超越...
后面就无私地帮助别人啦! 🙂
后面说的话
其实这次比赛还是有挺多遗憾的...
首先觉得自己并没有学到什么,只是做到了简单的调参和寻找其他模型,并没有对AI具体实现有更深层次的了解
其次是最后因为AP考试的缘故,没有上交复现报告,所以最终排名应该不会出现我们队的名字...
(听闻前两名选手TLE了是真的吗?早知道交了草)
无论如何,努力了还是坠吼滴!继续加油!
版权声明:
作者:carott
链接:https://blog.hellholestudios.top/archives/571
来源:Hell Hole Studios Blog
文章版权归作者所有,未经允许请勿转载。
共有 0 条评论