
【OI的里技#2】vector测速
0.声明
算法第一 常优第二
C++是算法的载体,为算法服务。本系列的目的不在于推崇常优,而是解除OIer对常数的顾虑而专注于算法。
| 环境 | 编译参数 | 语言标准 | 优化等级 | |
|---|---|---|---|---|
| NOIP(2020) | i7-8700K @3.70GHz 32G NOI Linux 1.4.1 gcc 4.8.4 |
-lm | c++11 | O0 |
| NOIP(2021+) | i7-8700K @3.70GHz 32G NOI Linux 2.0 gcc 9.3.0 |
-lm | c++14 | O2 |
笔者钦定评测机 (Lenovo G410) |
i5-4120M @2.60GHz 4GB+8GB DDR3-1600 Ubuntu 20.04.3 LTS (Linux 5.4.0-89-generic x86_64) gcc 9.3.0 |
-lm | 可变 | 可变 |
上次使用了LOJ,感觉不是很优雅而且不能支持批量测试,因此这次增加了笔者钦定评测机。主要原因是笔者的日用笔记本装的是Win10,而MinGW下的chrono计时精度似乎有问题,而且有不同OS的差异以及AMD与Intel的CPU架构差异。如果用WSL的话又会担心虚拟机调度造成的overhead(虽然实际上还好)。最后笔者给老笔记本装了ubuntu当测试机(其实是装在U盘上的)。
1.方法
很抱歉更新时间慢于预期。在研究过程中发现的问题实在很多,尤其是发现循环展开会使性能提升约70%以及开不开register等细节问题。本来准备展开循环而且加register的,结果写到一半发现今年CSP居然开O2了。。于是不得不抛弃大多数O0下测得的数据重新测试,最后决定加register且展开循环,比较接近实际用法(循环体内多次操作)(反正NOIP开O2还关心什么register啊)。
由于CPU缓存的存在,数组测试在第二次访问时速度会极大地提高,因此有get1/get2与set1/set2之分(只有set1未写入缓存),而vector由于某些笔者搞不清楚的原因无法复现此现象(强制清空也没有显著效果,至少笔者做不到)。
CPU Turbo对结果也会有影响,但笔者实在做不了什么,顶多保证多组测试连续运行(CCF评测毕竟是连续测的)。
数据类型全部采用int,每组数据测10次取平均,原始数据见Google Docs。
2.分析
O0:
O2:

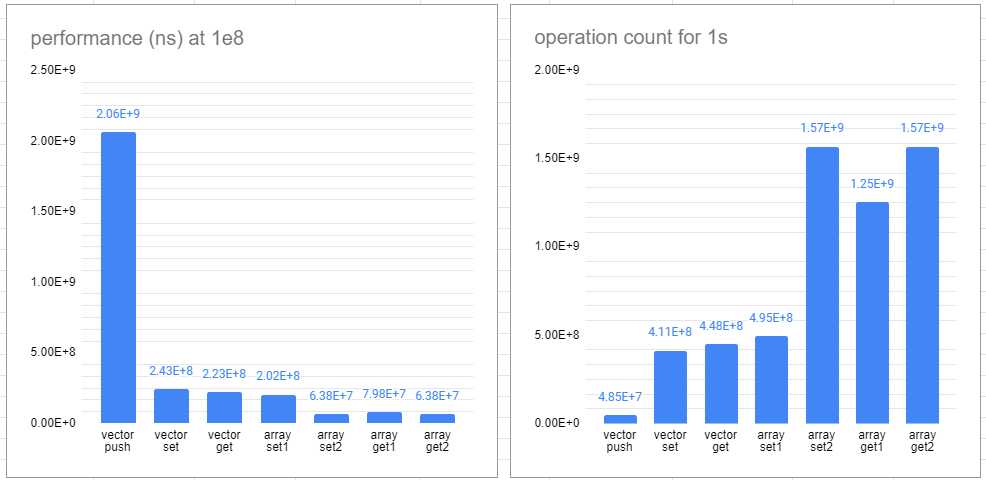
右图为各项在1e8操作下的执行时间,单位纳秒(10^{-9} s)
左图给出了估计的一秒内可执行操作数,各位实战时建议至少减半,尤其是考虑条件分支造成的性能缩水(这玩意还难以定量检测)。在理想情况下数组的性能实在超乎预期,达到了3e9。笔者粗略地测了IPC,高达2.2,可见在现代CPU流水执行的加持下1e9+操作不是梦((但是各位比赛时就不要幻想了,实战2e8差不多
可见在O2下vector与数组正常读写基本平起平坐,在O0下要慢近4倍。push_back非常拉跨,在O2下比无Cache数组慢约3.7倍,O0下几乎慢10倍。
总之vector肯定比数组慢,但是在O2时代并不明显,除了push_back。所以性能重要的时候还是老老实实地手写a[cnt++]=x吧。另外使用vector.reserve()解决动态内存分配问题可以提升一定性能,但是并不实用。
3.BONUS!!插入与删除
感觉这边意义不大我懒得测数组,但是测试都做好了就贴一下结果吧。
O2:

O0和O2基本相同就不贴了,估计是因为相比上面的测试,更多的执行时间交给了已经O2编译过的libc代码。
这玩意内部估计用了什么SSE魔法因此跑得飞快,单次操作在 0.16*移动元素数 ns左右。
版权声明:
作者:Zzzyt
链接:https://blog.hellholestudios.top/archives/663
来源:Hell Hole Studios Blog
文章版权归作者所有,未经允许请勿转载。
共有 0 条评论