
【OI的里技#1】常优分析: inline? register?
0.声明
算法第一 常优第二
C++是算法的载体,为算法服务。本系列的目的不在于推崇常优,而是解除OIer对常数的顾虑而专注于算法。
| 环境 | 编译参数 | 语言标准 | 优化等级 | |
|---|---|---|---|---|
| NOIP(2020) | i7-8700K @3.70GHz 32G NOI Linux 1.4.1 gcc 4.8.4 |
-lm | c++11 | O0 |
| NOIP(2021+) | i7-8700K @3.70GHz 32G NOI Linux 2.0 gcc 9.3.0 |
-lm | c++14 | O2 |
| LOJ(新版) | ???@3.79GHz 5941 MiB Linux 5.10.0-8-amd64 gcc ???(可能8.3.0) |
??? | 可变 | 可变 |
LOJ貌似是AMD的机器,与8700k架构上会有差异,但是笔者实在找不到能与新版LOJ自定义程度相比的OJ了,就这样吧。
1. x++ vs ++x
先搞点简单的罢
据说for(int i=0;i<n;++i)比for(int i=0;i<n;i++)更优,因为i++需要暂存i在自增前的值?
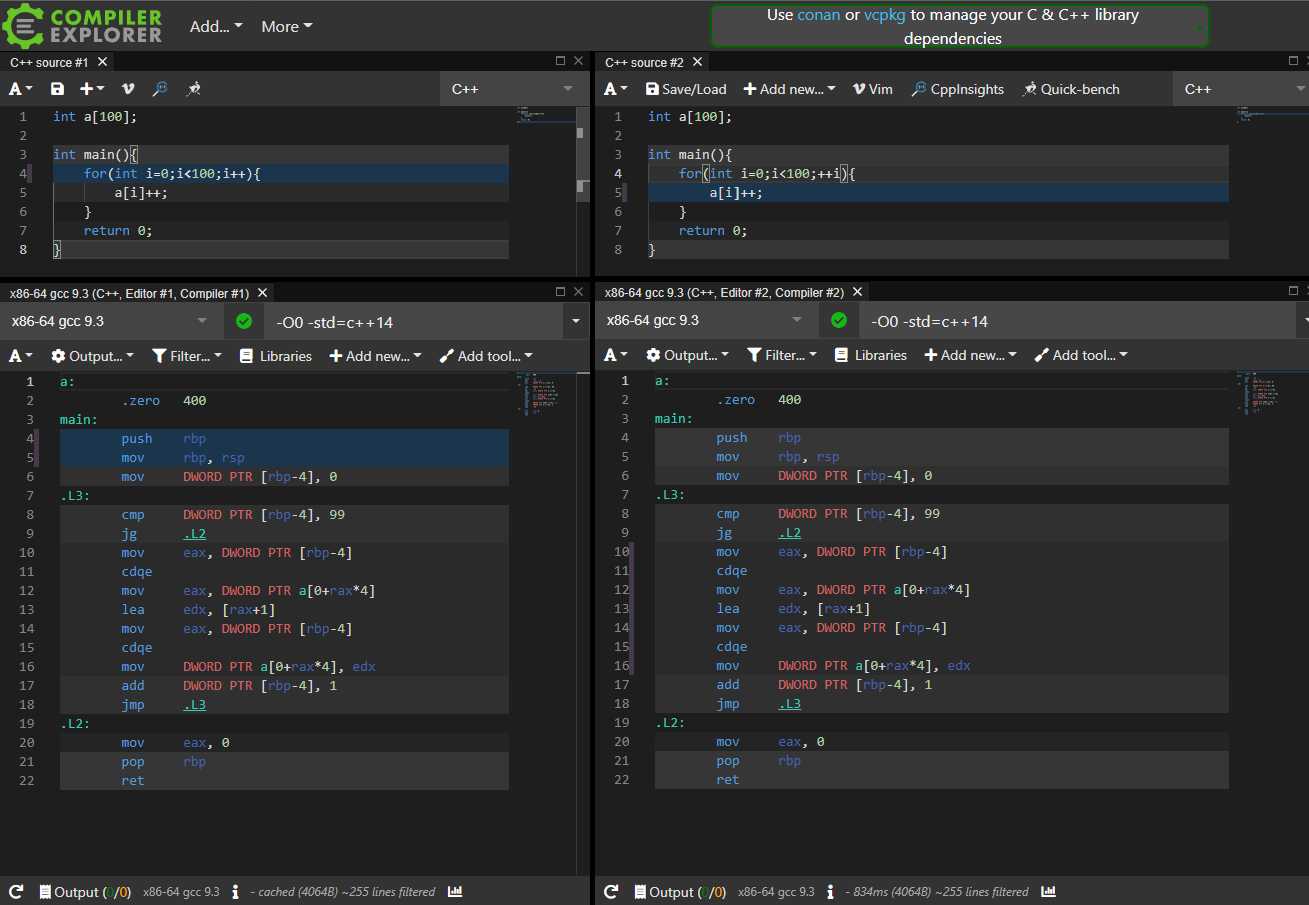
在一切优化等级和标准下都完全一致。
当然使用返回值的时候机器码会有所不同,但性能差距微乎其微(而且使用这种极易混淆的写法心里不慌吗 你记得住哪个先返回哪个后返回吗)
UPD: 另一种讲法是STL的迭代器自增运算有性能差异:
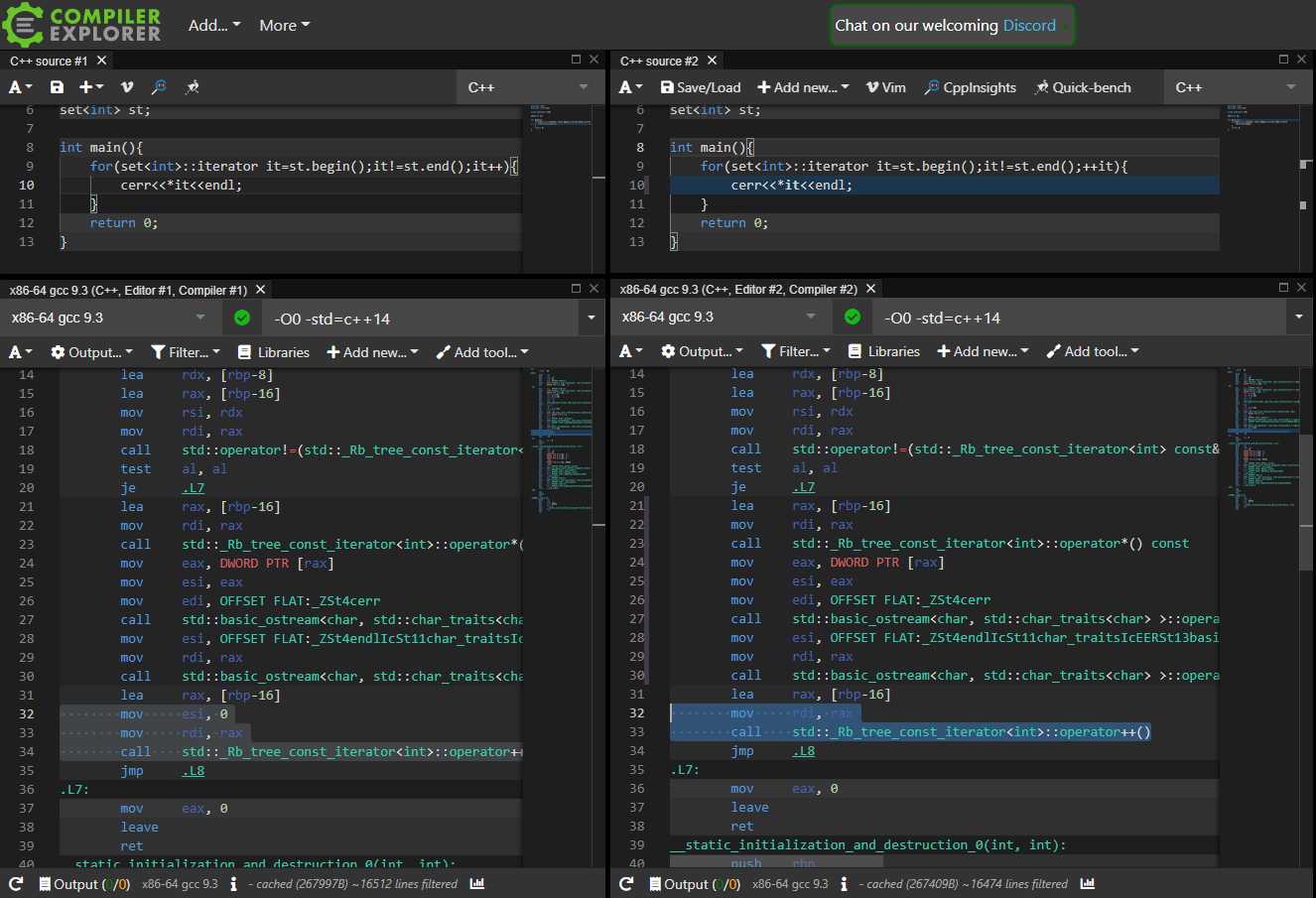
```c++
_Self&
operator++() _GLIBCXX_NOEXCEPT
{
_M_node = _Rb_tree_increment(_M_node);
return *this;
}
_Self
operator++(int) _GLIBCXX_NOEXCEPT
{
_Self __tmp = *this;
_M_node = _Rb_tree_increment(_M_node);
return __tmp;
}
[libstdc++源码出处](https://github.com/gcc-mirror/gcc/blob/dfe1ac896af0452706d29e20c593599ed3b09244/libstdc%2B%2B-v3/include/bits/stl_tree.h#L365)
O0下确有差异,但O2下就一样了:
[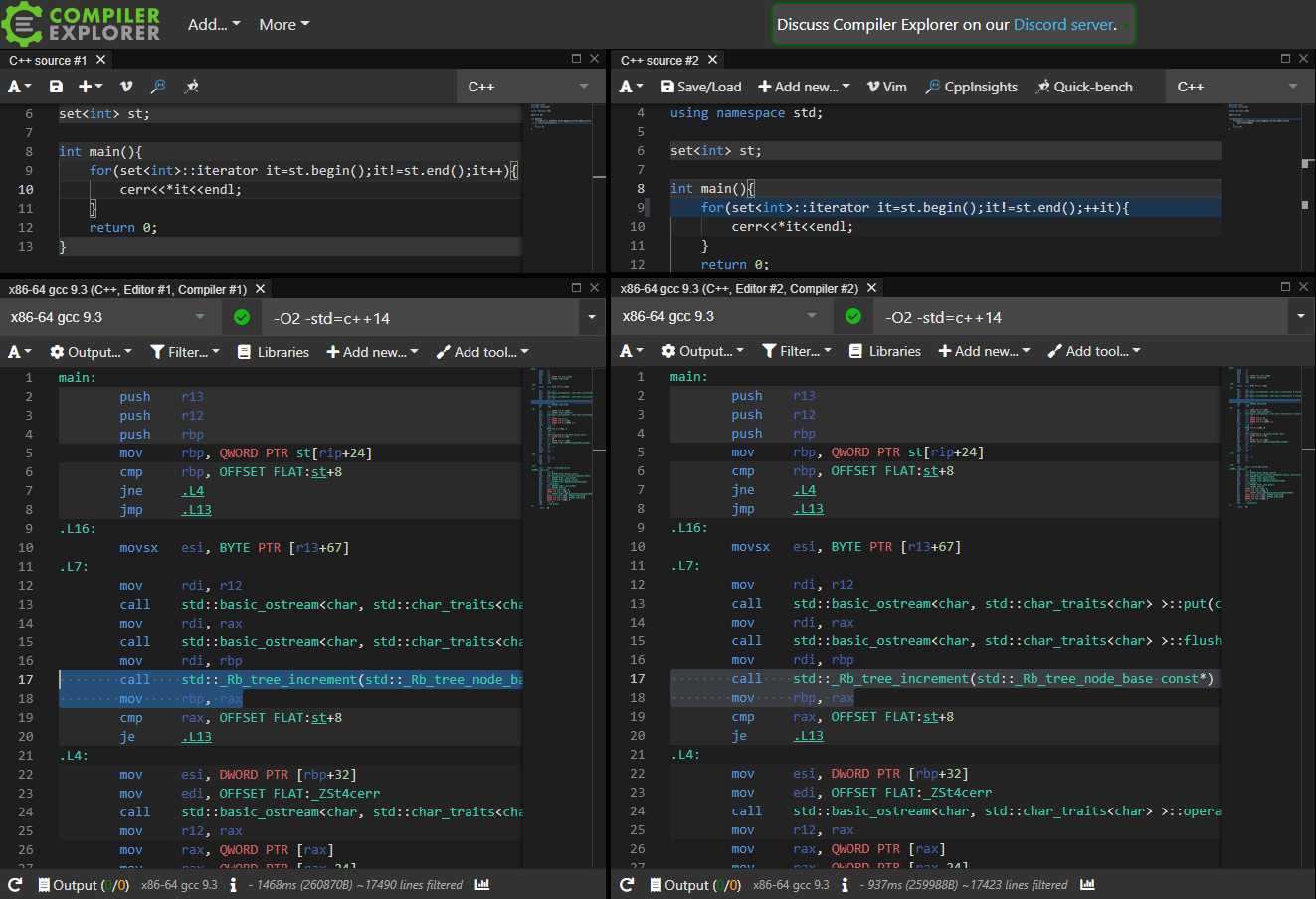](https://blog.hellholestudios.top/wp-content/uploads/2021/10/wp_editor_md_0316d9e65ad772612cd0c576e8c25ea9.jpg)
[Compiler Explorer](https://gcc.godbolt.org/z/vW9Yz451b)
可以测得差别,但不是很大,在5%左右。
[it++](https://loj.ac/s/1281009)
[++it](https://loj.ac/s/1281010)
[](https://blog.hellholestudios.top/wp-content/uploads/2021/10/wp_editor_md_aa471276c891e0043c242c46206ddc9e.jpg)
# 2.循环体内定义变量
据说`for(int i=0,x;i<n;i++){}`优于`for(int i=0;i<n;i++){int x;}`?~~真的有(可观数量的)人这么说吗~~
我是听说过“重复”定义变量会变慢这种说法的,放在Python里也许有效,但是C++不可能如此智障:
[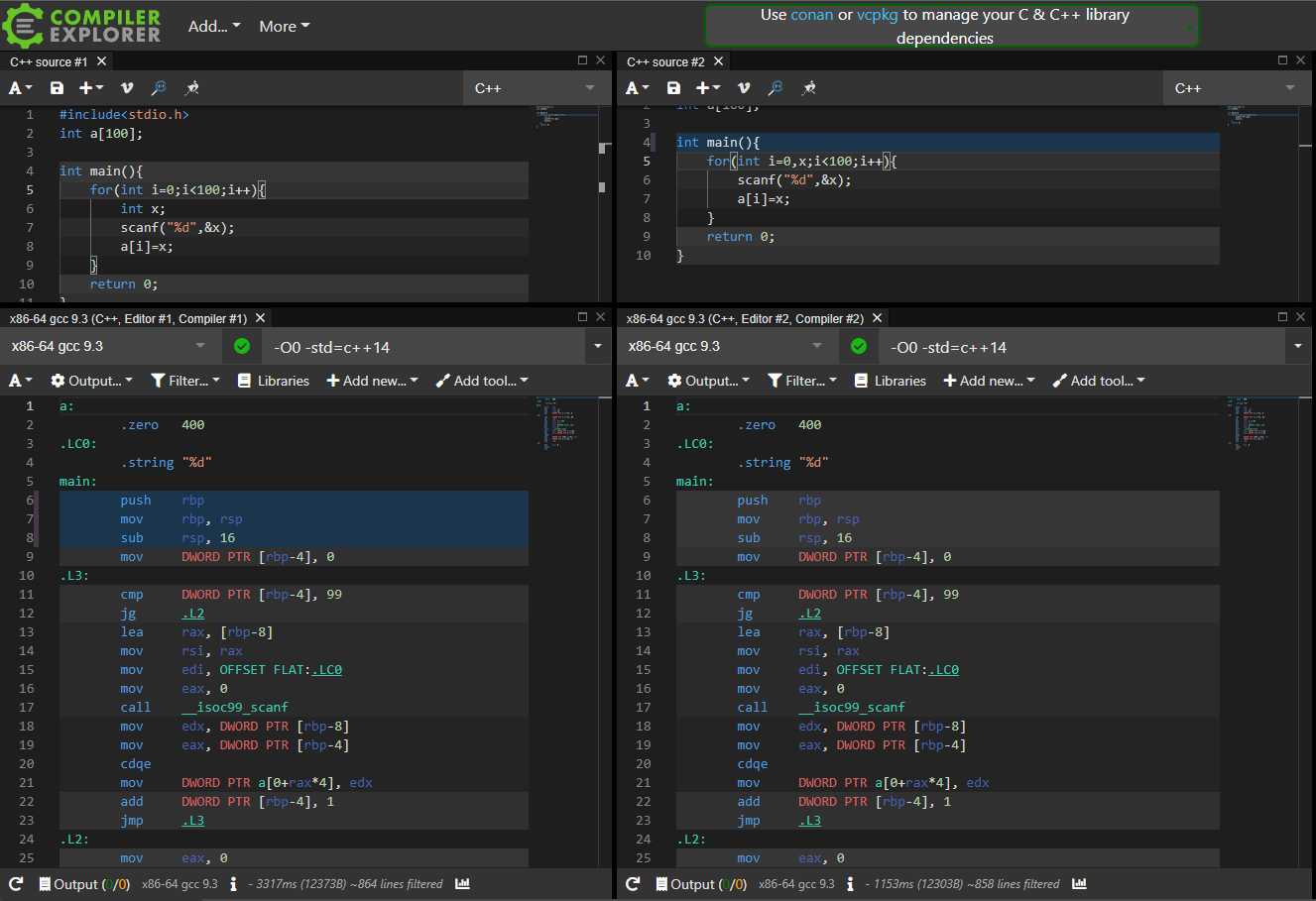](https://blog.hellholestudios.top/wp-content/uploads/2021/10/wp_editor_md_7aaa304b0cf436fd251ae9d85c85e4bc.jpg)
[Compiler Explorer](https://gcc.godbolt.org/z/97rax56Pj)
完全一致,结案。
# 3.register有用吗?
事情变得有意思起来了。
> `register`提示编译器将修饰的变量置于CPU寄存器内
在`O0`下,**`register`有效:**
[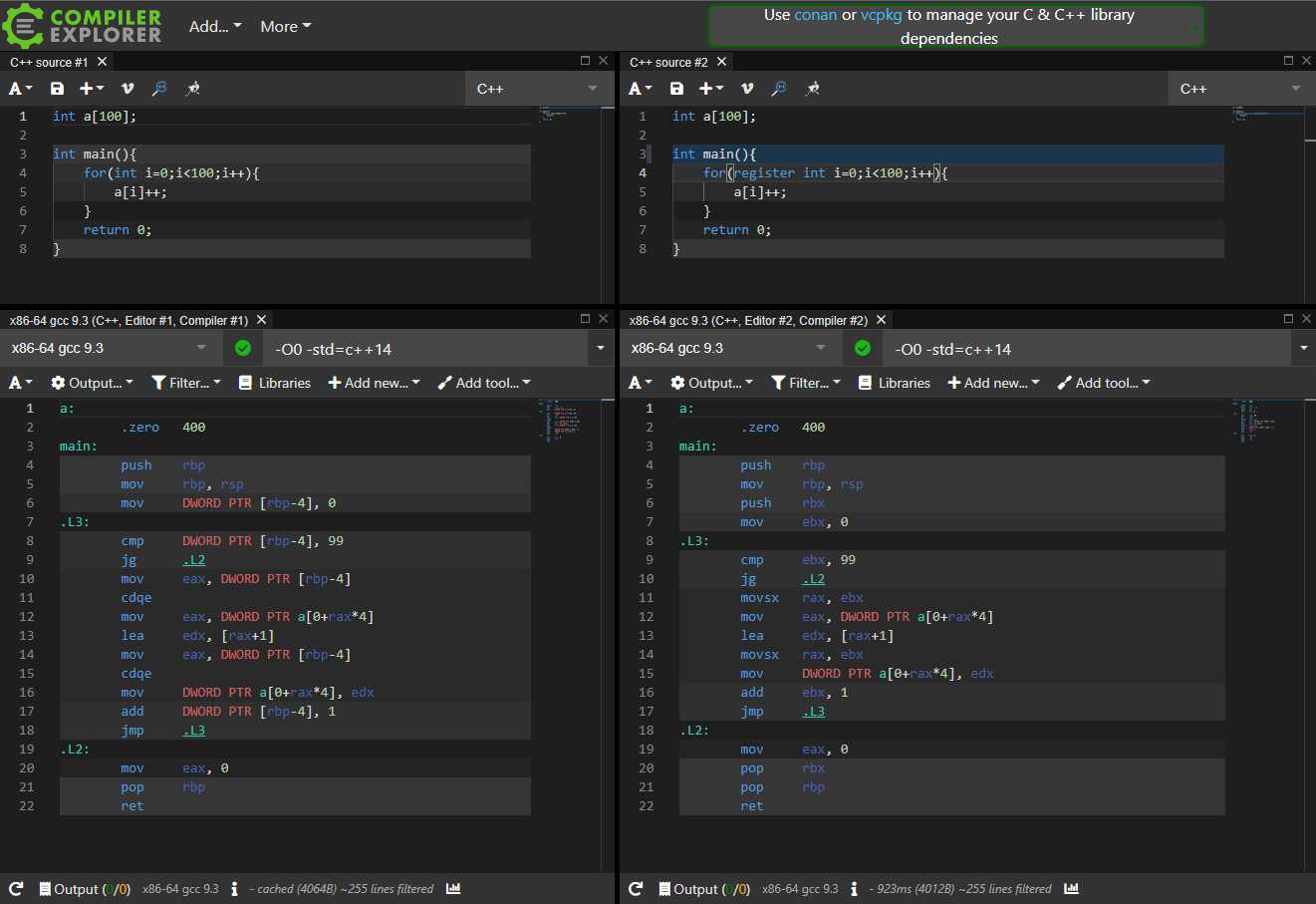](https://blog.hellholestudios.top/wp-content/uploads/2021/10/wp_editor_md_6ffe4142a33c58d2719f43b1777a0fe0.jpg)
[Compiler Explorer](https://gcc.godbolt.org/z/Kxh4jYfKx)
可以看出g++确实改用了寄存器(`DWORD PTR`变为`ebx`寄存器)
[](https://blog.hellholestudios.top/wp-content/uploads/2021/10/wp_editor_md_4b487895afd38c54662f61fa48f34c29.jpg)
[Compiler Explorer](https://gcc.godbolt.org/z/dTcGMPxdx)
然而在**`O1`及以上**,g++非常聪明地自动使用了寄存器。
`register`是非常落后的技术,从c++11起就已经deprecated,在c++17中更是被明确标注为未使用。`O0`的初衷是使得生成的机器码更贴近源代码的字面意思,并使得调试更容易,而不会关心运行速度。因此你不写`register`就是使用内存,写了就是使用寄存器,与源码完全对应。当然在NOIP的`O0`环境中我们只能退而求其次了。
那么`register`究竟比内存快多少?
```cpp
#include <iostream>
using namespace std;
int main() {
register int ans = 0;
int a, b;
cin>>a>>b;
for(register int i=0;i<1000;i++){
for(register int j=0;j<1000;j++) {
for(register int k=0;k<500;k++) {
ans++;
}
}
}
cout<<a+b<<endl;
return 0;
}

无register
循环变量register
全register
给循环变量加上register后时间减少14%,给ans也加上则是45%。

笔者找了一道dp题并暴力地加了一堆register,对于500ms的大点能够减少10%-20%的时间。
综上,在O0下register有可观的效果,各位NOIP卡时骗分时不妨一试。

然而这些小技俩在O2面前根本不值一提。CCF什么时候能开O2啊(幻想
4.inline
inline的作用不止一种,但在OI中主要是起到提示编译器将函数嵌入调用上下文的作用,以可执行文件大小换时间。
悲惨的是,inline在O0下完全无效(除非你使用__attribute__((always_inline))之类的暴力方法):
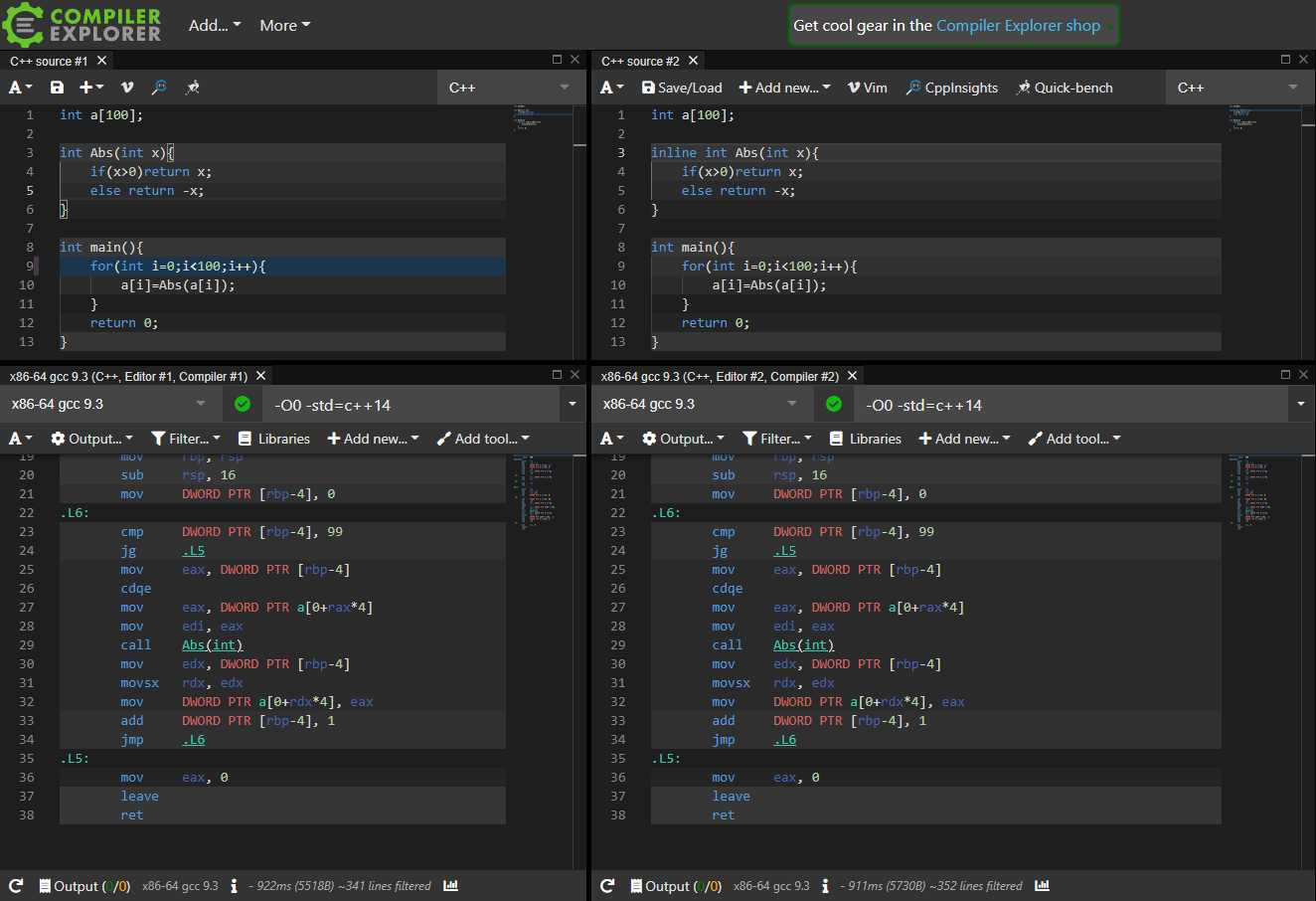
而在O1及以上,二者都被inline了,只是没加inline的函数没有被删除(依然可以被其他代码正常调用,比如作为库使用)

所以inline貌似(对于OI来说)是完全无效的。对于G++自动inline更大函数的机制我并不了解,但是对于更大的函数来说调用的时间远小于函数本体执行的时间,inline的意义也就不大了。
什么时候把STL也测一遍呢(
版权声明:
作者:Zzzyt
链接:https://blog.hellholestudios.top/archives/661
来源:Hell Hole Studios Blog
文章版权归作者所有,未经允许请勿转载。
共有 0 条评论